Open Your Business Rules!
Rules-based
Operational Decision Services
OpenRules Classic: Rule Learner
Integrated Machine Learning and Business Rules approach
Motivation
Over the
last several years, the field of Machine Learning
(ML) has attracted considerable attention due to
the demand for reliable and useful data mining
techniques in information technology, health care, and
several other industries. Today's ML offers
powerful algorithms and tools for practical knowledge
discovery. However, when delivered as a
stand-alone application, this highly complicated process
for identifying potentially useful patterns from large
collections of data remains the prerogative of
scientists and has yet to penetrate the major business
decision making processes in the way that the Business
Rules (BR) approach has already done.
One of the most popular
techniques of ML is the extraction of
classification rules and patterns from massive data
sets; the module that does this work is called a Rule
Learner. At the same time, rules discovery is
an important component of an enterprise Business Rules and
Decision Management System. This suggests a natural
question: Why not combine these two technologies (ML
and BR)? OpenRules answers this question with
a Rule Learner BRMS component and practical integration
tools.
ML+BR
Integration
An
integrated ML+BR approach at the highest level is
depicted in the following graphic:
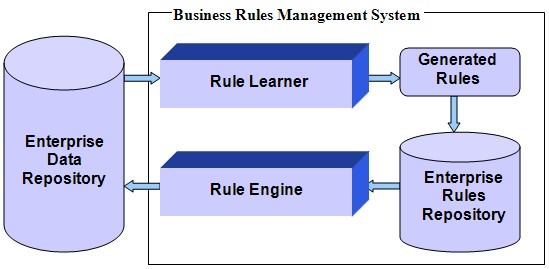
Here a Rule Learner is a special BRMS component that executes a machine learning algorithm against historical data coming from an Enterprise Database and generates (learns) new decision rules in a form that can be understood by both business specialists and the business rules system. The generated rules can be automatically added to the Enterprise Rules Repository to be used during a Rule Engine execution cycle to produce new business decisions that will in turn be saved to the Enterprise Data Repository. By working together and applying multiple iterations of the described process, we can see that Rule Learner and Rule Engine add a new dimension, that of self-improving learning capabilities, to rules-based business processes.
In this way a Rule Learner becomes an integral part of an enterprise level BRMS. It converts a rules-based decision service into a good "employee" of the enterprise, i.e., one that can learn from the previous experiences of its human "colleagues" and can also learn from its own previous experiences.
BRMS Architecture with a Rule Learner
OpenRules Rule Learner is based on a supervised Machine
Learning approach that requires
Training Sets for its execution. The resulting
integrated architecture is presented in the following
figure:
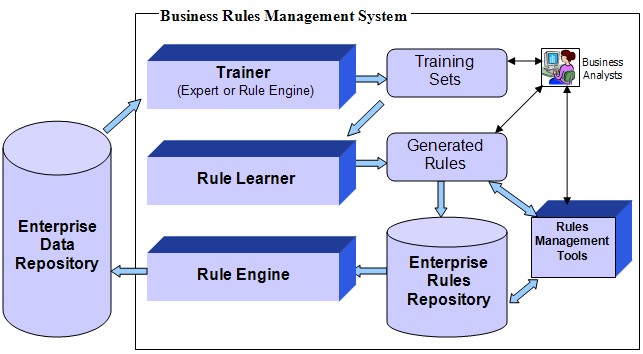
Training Sets. A Training Set usually consists of examples indicating when the desired result has been achieved (positive examples) and counter examples indicating cases when the desired result has not been achieved (negative examples). Training sets are used by the Rule Learner to discover and represent new rules and to measure the accuracy and effectiveness of the rules once they have been learned. If the results are satisfactory, the rules can then be used to predict results for new, previously unseen cases.
OpenRules Trainer. Supervised learning requires a Trainer to create training sets. Usually a Trainer is a subject matter expert (SME) who has extensive experience dealing with the historical enterprise data and has the competence and skills to establish goals, concepts, and/or criteria, for detecting patterns and rules. It is also possible to automate the Trainer function and make it an integral part of the system architecture. Initially, the Trainer can be implemented as an interactive rules-based interface that assists the subject matter expert in analyzing enterprise data and in creating training sets. But Trainer can also be implemented as a special rule engine that automatically analyses large volumes of data in accordance with "training rules" created by a SME and uses this data to generate new training sets. This is especially important for rules-based applications that frequently update enterprise data and would like their rule learner to keep up to date with the latest changes.
The OpenRules Trainer allows domain experts to incorporate their knowledge into Rule Learner by presenting it in a form of domain-specific training rules. Training Rules usually cover the following common data pre-processing tasks:
-
Selection of issues and attributes to be considered by a Rule Learner
-
Generation of new attributes that generalize the existing attributes by adding nominal attributes, ratios, etc.
-
Preliminary classification of issues
-
Instance filtering rules
-
Selection of Rule Learner execution parameters.
By making changes to training rules domain experts effectively inform Rule Learner about changes in the real-world environment. Here is a generic implementation schema used by the OpenRules Trainer:
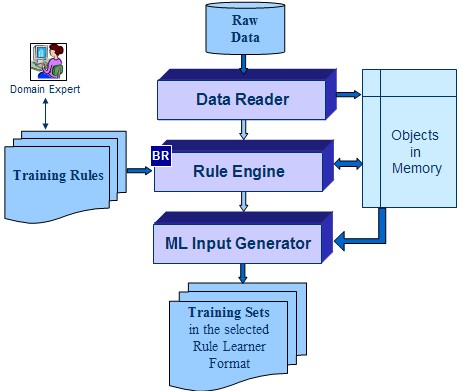
It is important to stress the fact that it is business specialists (NOT software developers) who are normally responsible for maintaining training sets and for evaluating automatically generated rules.
BRMS Architecture with a Rule Learner
OpenRules developed all the necessary components for an
integration of ML + BR that allow an enterprise to
combine different learning algorithms and rule engines.
Below is an integration schema that combines a
rules-based trainer with an automatic conversion of
learned rules into the BRMS:
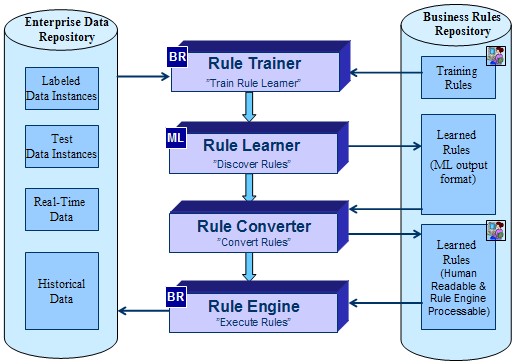
Here Rule Trainer may produce training sets in different ML formats that become an input for a selected ML tool. Rule Converter can parse the output of a selected Rule Learner and convert the learned rules into a format that can be used by a selected rule engine. Below is the implementation schema of a rule converter that uses WEKA as the Rule Learner implementation and OpenRules as the resulting Rule Engine:
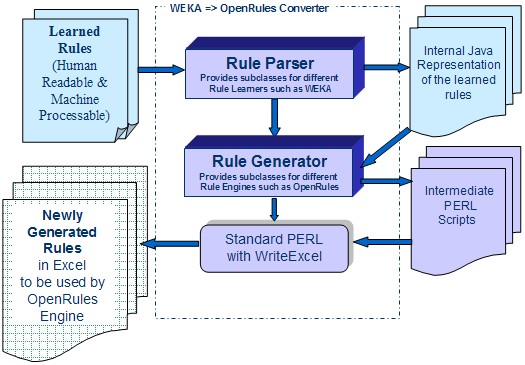
Machine Learning Algorithms and
Tools
OpenRules pioneered the
integration of ML and BR by including the first
practical implementation of a Rule Learner to its
popular open source BRMS. While there are many ML
algorithms and implementation tools, there is no known
algorithm that is optimal for ALL types of data sets.
In most cases, serious data analysis, as well as data
cleaning and tuning are needed. It is also to be
expected that different ML algorithms may behave
differently on the same data set. To support these
real-world needs, OpenRules does not limit an
implementation of its Rule Learner to only one
particular ML algorithm. It has been designed to accept
different ML algorithms and different input/output
formats. The current version of Rule Learner works
with the popular open source machine learning framework
"WEKA"
that implements many well-known ML algorithms such as
C4.5 and RIPPER. Other popular ML tools are under
consideration and can be added on an as needed basis.
Because it is an integral part of OpenRules, Rule Learner follows the major OpenRules principles: it is designed to be used by business analysts (not only programmers) and it is designed to be presented or manipulated using commonly accepted tools such as Excel without the introduction of new languages. Rule Learner (as well as Rule Engine) can be deployed as a Web Service using the standard OpenRules deployment facilities. These principles make Rule Learner a good citizen of the service-oriented world because customers can decide when and how to invoke ML and BR services from their own business processes.
Rule Compressor
OpenRules applied the integrated ML+BR
approach to create a special OpenRules add-on
Rule Compressor™ that may
compress complex classification rules regardless of
which BRMS is being used - read
more.
Benefits. OpenRules successfully integrates ML and BR approaches without forcing business analysts to become machine learning gurus or to learn new languages and/or new software tools. OpenRules' Rule Learner integrates ML and BR approaches with the ability to automatically transition learned rules into the enterprise’s rule management system. When an enterprise begins to use Rule Learner and Rule Engine together, its own Subject Matter Experts can examine the generated rules to determine why they make sense or if they should be supplemented by additional rules. Once the applicability of Rule Learner to detecting patterns and decision rules in a particular data base has been established, automating the rule generation and execution processes becomes an enormous asset.
Services. OpenRules can help an enterprise to jump-start the use of an integrated ML+BR solution. We provide professional services to assist customers in specifying and implementing their specific rules discovery program and to assist in integrating ML+BR into their business processes. Even if your enterprise does not use OpenRules and has already made an essential investment in a commercial BRMS, OpenRules specialists can assist in incorporating the Rule Learner into another BRMS.
